Random Read Vs Sequential Read in Ceph
Kubernetes Storage Performance Comparison v2 (2020 Updated)
In 2019 I published a blog: Kubernetes Storage Performance Comparison. My goal was to evaluate the near mutual storage solutions available for Kubernetes and perform basic operation testing. I had results for GlusterFS, CEPH, Portworx and OpenEBS (with cStor backend). This web log has been popular and I received a lot of positive feedback. I've decided to come dorsum with few updates on progress in the storage community and their performance numbers, which I promised in my last web log. I extended my testing scope to include two more than storage solutions:
- OpenEBS MayaStor
- Longhorn
Let's start with the storage backend updates and their installation description, and so nosotros will get over the AKS testing cluster environment and present the updated operation results at the finish.
Storage
As of Jan 2019, the CNCF storage landscape and solutions have changed. It has grown from thirty to 45 solutions nether the storage imprint, there were also governance expansions of public deject integrations such as AWS EBS, Google persistent disk or Azure disk storage. Some of the new solutions focused more towards distributed filesystem or object storage equally Alluxio. My original goal, and continues to be the same, is to evaluate block storage options. Permit'due south revisit my original listing.
GlusterFS Heketi was second worst in functioning results and its improvements are zero and information technology is mostly a expressionless project (Heketi as Remainder orchestrator not GlusterFS itself). If you expect at their official GitHub, yous can run across that they are placing it into a most-maintenance fashion and at that place is not any update in terms of cloud-native storage features.
PortWorx remains still in the top commercial storage solutions for Kubernetes according to the GIGAOM 2020 study. However there hasn't been a pregnant engineering or architecture alter claimed in release notes between versions 2.0 and ii.five from a performance signal of view.
The best open source storage, CEPH orchestrated via Rook, produced 2 new releases and introduced a new CEPH version called Octopus. Octopus brings several optimizations in caching mechanisms and uses more modern kernel interfaces (See more at the official page).
The only major compages change happened in OpenEBS, where it introduced a new backend called MayaStor. This backend looks very promising.
I also received a lot of feedback from the community on why I did not exam Longhorn from Rancher. Therefore I decided to add to my telescopic.
I evaluated Longhorn and OpenEBS MayaStor and compared their results with previous results from PortWorx, CEPH, GlusterFS and native Azure PVC. The following subsection introduces storage solutions added into the existing test suite. It also describes installation procedure and advantages/disadvantages of each solution.
Longhorn
Longhorn is deject-native distributed block storage for Kubernetes, developed past Rancher. It was designed primarily for microservices use cases. It creates a dedicated storage controller for each block device volume and synchronously replicates the book across multiple replicas stored on multiple nodes. Longhorn creates a Longhorn Engine on the node where book is attached to, and it creates a replica on a node where volume is replicated. Similar to others, the unabridged control plane runs and the information aeroplane is orchestrated past Kubernetes. It is fully open source. It's interesting that OpenEBS Jiva backend is actually based on Longhorn or at least initially it was its fork. The chief difference is that Longhorn uses TCMU Linux driver and OpenEBS Jiva uses gotgt.
How to get it on AKS?
Installation to AKS is piddling
- Run one command and information technology install all components into my AKS cluster
2. Mount /dev/sdc1 with ext4 filesystem into /var/lib/longhorn, which is the default path for volume storage. It is better to mount the deejay there earlier Longhorn installation.
three. The terminal step is to create a default storage class with 3 replicas definition.
Advantages
- Open source
- Cloud-native storage — information technology can run on HW clusters too as public clouds.
- Piece of cake to deploy — it requires a single control and "it simply works" out of the box.
- Automatic volume backup/restore into S3
Disadvantages
- It uses mount point into /var/lib/longhorn with a standard filesystem (ext4 or xfs). Each book is similar a single disk file. It scales with a number of controller replicas, which tin bring actress networking overhead. Similar to what I described for OpenEBS Jiva.
- Mounting of volumes sometimes takes a long fourth dimension (few minutes) and it is showing errors which information technology eventually recovers from.
OpenEBS MayaStor
OpenEBS represents the concept of Container Attached Storage (CAS), where in that location is a unmarried microservice-based storage controller and multiple microservice-based storage replicas. If you read my previous weblog postal service from 2019, you lot know that I was playing two backends — Jiva and cStor. I concluded up using cStor and its performance results were actually bad. However 1.five years is a long time and the OpenEBS team introduced a new backend chosen MayStor.
It'southward a cloud-native declarative information plane written in Rust, which consists of 2 components:
- A control plane implemented in CSI concept and data plane. The main difference compared to the previous backend is leveraging NVMe over Fabrics (NVMe-oF), which promises to provide much amend IOPS and latency for storage sensitive workloads.
- Another advantage of this storage pattern is that it runs completely out of the kernel in the host userspace and removes differences acquired by the variety of kernels bachelor in dissimilar Linux distributions. It simply does not depend on the kernel for access. I establish a overnice design explanation of MayStor in this web log.
How to get it on AKS?
Installation on AKS is straight frontwards, and I followed their quick start guide.
- I had to configure 2MB Huge Pages with 512 numbers on each node in my AKS cluster.
echo 512 | sudo tee /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
However I decided to enforce them via k8s daemonset beneath instead of ssh into every my instance.
2. I had to label my storage node VMs.
3. And so I practical all manifests specified in MayaStor repository.
4. When everything is running, you can start creating storage pools for volume provisioning. In my case I created 3 storage pools with a unmarried disk per node.
v. It is important to check the status of each storage pool before you lot can proceed with StorageClass definitions. State must exist online.
6. The last stride in the process is StorageClass definition, where I configured three replicas to have same testing environs equally for my previous storage solutions.
Subsequently I had finished these steps I was able to dynamically provision a new volumes via K8s PVC.
Advantages
- Open source with great community support
- Cloud-native storage — information technology can run on HW clusters as well as public clouds.
- Usage of NVMe which is designed for high parallelism and can have 64K queues compared to SCSI which has merely one queue.
- It uses NVMe-oF as transport which can work on a variety of transports (nvmf, uring, pcie) and it is fully done in user space — target besides equally the initiator. Running in user infinite can avert a large amount of system calls, mail spectere/meltdown, etc. Also information technology is kernel independent, so at that place is no difference between type of linux beyond cloud or physical environment.
Disadvantages
- Early versions — OpenEBS MayaStor is at version 0.three, so it still has some limitations and stability issues. However they are on the correct track and in a few months information technology tin can be peak choice for storage in K8s.
- It's required to have support for 2MBs Hugepages on Kubernetes nodes. However compared to 1GB hugepages, this is bachelor nearly in all environments concrete or virtual.
Performance Results
Important NOTE: The results from individual storage functioning tests cannot be evaluated independently, merely the measurements must be compared against each other. There are various ways to perform comparative tests and this is one of the simplest approaches.
For verification I used exactly the same lab with Azure AKS 3 node cluster and 1TB premium SSD managed disk attached to each instance. Details you can find in the previous web log.
To run our tests I decided to utilize the same load tester chosen Dbench. It is K8s deployment manifest of pod, where it runs FIO, the Flexible IO Tester with viii test cases. Tests are specified in the entry bespeak of Docker epitome:
- Random read/write bandwidth
- Random read/write IOPS
- Read/write latency
- Sequential read/write
- Mixed read/write IOPS
At the start, I ran Azure PVC tests to get a baseline for comparison with last yr. The results were most the same, therefore we can presume weather condition remained unchanged and we would attain the aforementioned numbers with the aforementioned storage versions. Updated total test outputs from all tests from 2019 plus new MayStor and Longhorn tests are available at https://gist.github.com/pupapaik/76c5b7f124dbb69080840f01bf71f924
Random read/write bandwidth
Random read exam showed that GlusterFS, Ceph and Portworx perform several times better with read than host path on Azure local deejay. OpenEBS and Longhorn perform almost twice better than local disk. The reason is read caching. The write was the fastest for OpenEBS, however Longhorn and GlusterFS got also most the same value every bit a local disk.
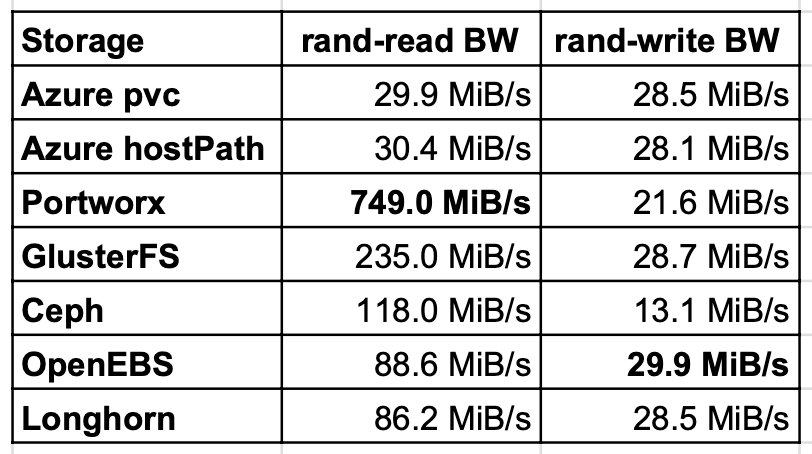
Random read/write IOPS
Random IOPS showed the best result for Portworx and OpenEBS. OpenEBS this time got even improve IOPS on write than native Azure PVC, which is nigh technically impossible. Virtually probably it is related to Azure storage load at different times of examination example runs.
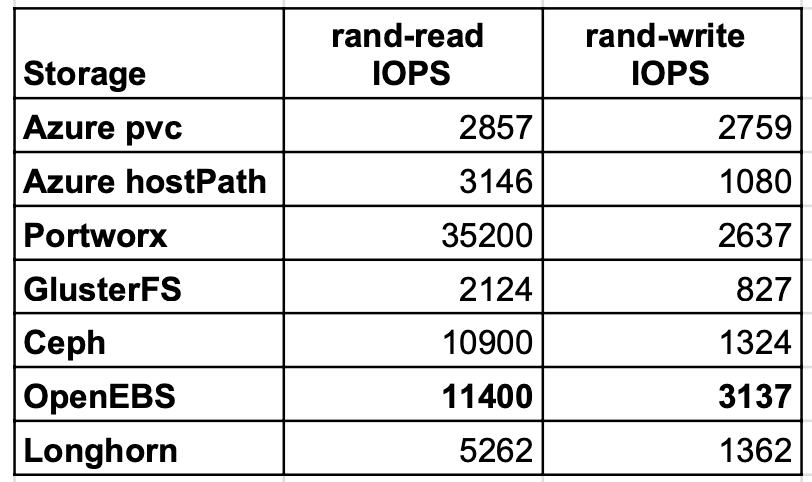
Read/write latency
Latency read winner remained the same as last time. LongHorn and OpenEBS had almost double of PortWorx. This is even so keen since native Azure pvc was slower than most of the other tested storages. However latency during write was improve on OpenEBS and Longhorn. GlusterFS was still better than other storages.
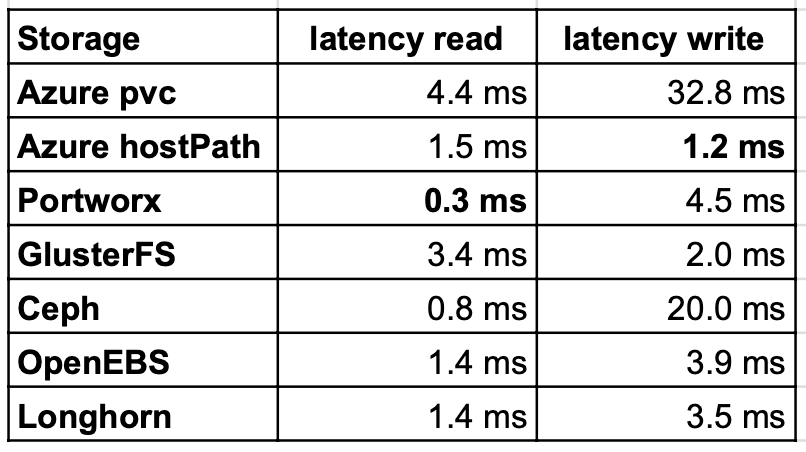
Sequential read/write
Sequential read/write tests showed similar results as random tests, notwithstanding Ceph was 2 times ameliorate on read than GlusterFS. The write results were almost all on the same level and OpenEBS and Longhorn achieved the aforementioned.
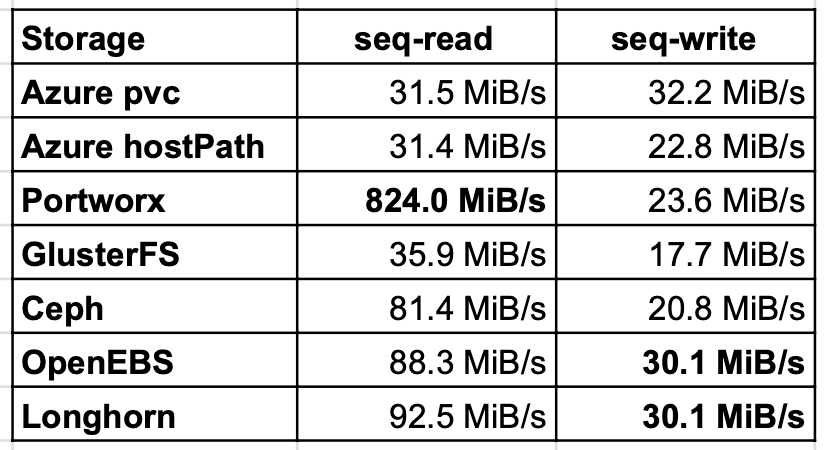
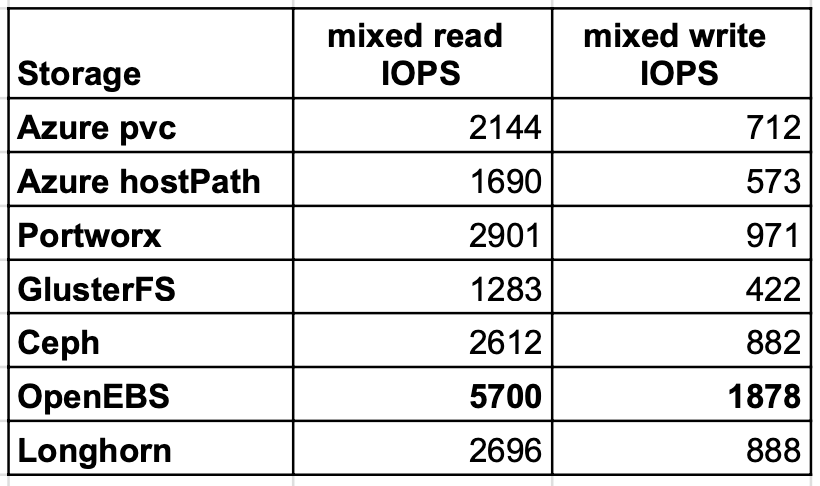
Mixed read/write IOPS
The last test case verified mixed read/write IOPS, where OpenEBS delivered almost twice higher than PortWorx or Longhorn on read every bit well every bit write.
Decision
This blog shows how significantly an open source project tin can change in a single yr! Every bit a demonstration let's take a expect at comparing of IOPS between OpenEBS cStor and OpenEBS MayaStor on exactly the same environment.
Please have the results just as one of the criteria during your storage selection and practise not make final sentence just on my web log data. To extend my terminal summary from 2019 on what nosotros tin conclude from the tests:
- Portworx and OpenEBS are the fastest container storage for AKS.
- OpenEBS seems to go one of the best open source container storage options with a robust design effectually NVMe.
- Longhorn is definitely a valid option for simple block storage use cases and it is quite like to OpenEBS Jiva backend.
Of course this is just one way to look at container storage selection. The interesting parts are also scaling and stability. I volition go along an eye on other evolving projects in the CNCF storage landscape and bring new interesting updates from performance testing and scaling.
johnswoperand1967.blogspot.com
Source: https://medium.com/volterra-io/kubernetes-storage-performance-comparison-v2-2020-updated-1c0b69f0dcf4
Postar um comentário for "Random Read Vs Sequential Read in Ceph"